

An AI chatbot may answer hundreds of customer questions correctly, but one wrong response about pricing, eligibility, policy, or personal data can create a serious business risk. For UAE enterprises, launching AI-powered software is no longer just a technology decision. It is a trust, compliance, and customer experience decision.
AI software testing helps validate whether AI chatbots, AI agents, LLM applications, voice assistants, and intelligent automation workflows are accurate, safe, secure, reliable, and ready for real users before launch.
This checklist is designed for enterprise teams preparing to launch or scale AI-powered systems. It focuses on the risks traditional software testing may miss, from Hallucination and Data Leakage to Multilingual Quality, Human Escalation, Workflow Integration, and Post-Launch Monitoring.
What AI Software Testing Really Means for AI-Powered Systems
AI software testing can mean different things depending on the context. In this checklist, it refers specifically to testing software systems that contain AI capabilities. These may include AI chatbots, AI agents, LLM-based applications, recommendation engines, voice assistants, intelligent document processing systems, computer vision applications, or AI-powered workflow automation.
The goal is not only to confirm that the software runs as expected. It is to validate whether the AI behaves correctly, safely, and consistently in real business situations. Can the system provide accurate answers? Can it avoid unsafe or misleading responses? Can it protect sensitive data? Can it handle English and Arabic inputs properly? Can it escalate to a human when a situation becomes too complex, sensitive, or high-risk?
This is different from using AI to automate QA tasks. AI-generated test cases, self-healing test scripts, AI test automation tools, and AI-assisted regression testing are closer to the topic of AI in software testing. Those methods can help QA teams work faster, but they are not the main focus of this article.
Here, AI software testing means validating the AI-powered system itself before it reaches real users. For UAE enterprises, this distinction matters. An AI system can look impressive in a demo but still fail when exposed to real customer questions, sensitive business data, multilingual conversations, complex workflows, and compliance expectations.
Why AI-Powered Systems Need Stronger Testing in the UAE
AI-powered systems do not behave like traditional software. A standard application usually follows fixed rules: if the user clicks a button, the system performs a defined action. AI-powered software can respond differently depending on the prompt, user intent, available data, language, model behavior, and workflow context. This makes testing more complex.
For UAE enterprises, the risk is not theoretical. AI is increasingly used in customer service, fintech, logistics, healthcare, e-commerce, government services, and internal operations. Many of these systems are customer-facing or connected to sensitive workflows. A chatbot that gives the wrong policy answer, an AI agent that triggers the wrong process, or a document processing tool that extracts the wrong value can affect revenue, operations, compliance readiness, and customer trust.
Multilingual quality adds another layer. UAE businesses often serve users in English, Arabic, and mixed-language conversations. An AI system may perform well in English but misunderstand Arabic wording, local terminology, customer intent, or context. Without proper testing, these issues may only appear after launch.
This is why AI software testing needs to go beyond basic functional checks. The question is not only “does the system work?” The stronger question is: “Can this AI-powered system be trusted in real business conditions?”
The 10 AI Software Testing Checks Before Launch
Before launching an AI-powered system, enterprises need more than standard functional testing. The following 10 checks help teams validate whether an AI-powered system is ready for real business use.
1. Accuracy
Accuracy checks whether the AI provides correct information, recommendations, classifications, extracted data, or actions. For an AI chatbot, this may mean answering policy or product questions correctly. For an intelligent document processing system, it may mean extracting the right invoice value, customer name, date, or contract clause.
Ask: Does the AI output match verified business data? Can it handle incomplete or ambiguous input without guessing?
2. Hallucination
Hallucination happens when an AI system produces information that sounds confident but is incorrect, unsupported, or invented. A chatbot may create a fake policy. An AI assistant may invent a process. An LLM application may provide an answer that is not grounded in approved company data.
Ask: Does the AI admit uncertainty when it does not know the answer? Does it avoid inventing policies, prices, procedures, or links?
3. Bias and Fairness
AI-powered systems may behave inconsistently across user groups, languages, inputs, or customer profiles. A recommendation engine may favor certain profiles unfairly. A chatbot may provide more complete answers in English than in Arabic. A document review tool may misread some formats more often than others.
Ask: Are outputs fair across different scenarios? Does the AI behave consistently across English and Arabic inputs?
4. Safety
Safety means the AI should avoid harmful, misleading, inappropriate, or risky responses. This is especially important when AI systems interact with customers, employees, or regulated workflows. A safe AI system should know its boundaries and avoid giving advice outside its approved scope.
Ask: Does the AI refuse unsafe requests? Does it know when to ask for clarification or escalate?
5. Prompt Injection
Prompt Injection happens when a user tries to manipulate the AI into ignoring instructions, revealing hidden rules, bypassing restrictions, or performing unauthorized actions. This is a major risk for AI chatbots, LLM applications, AI agents, and tools connected to internal systems.
Ask: Can the AI be tricked into revealing hidden instructions? Can users force it to ignore business rules or security policies?
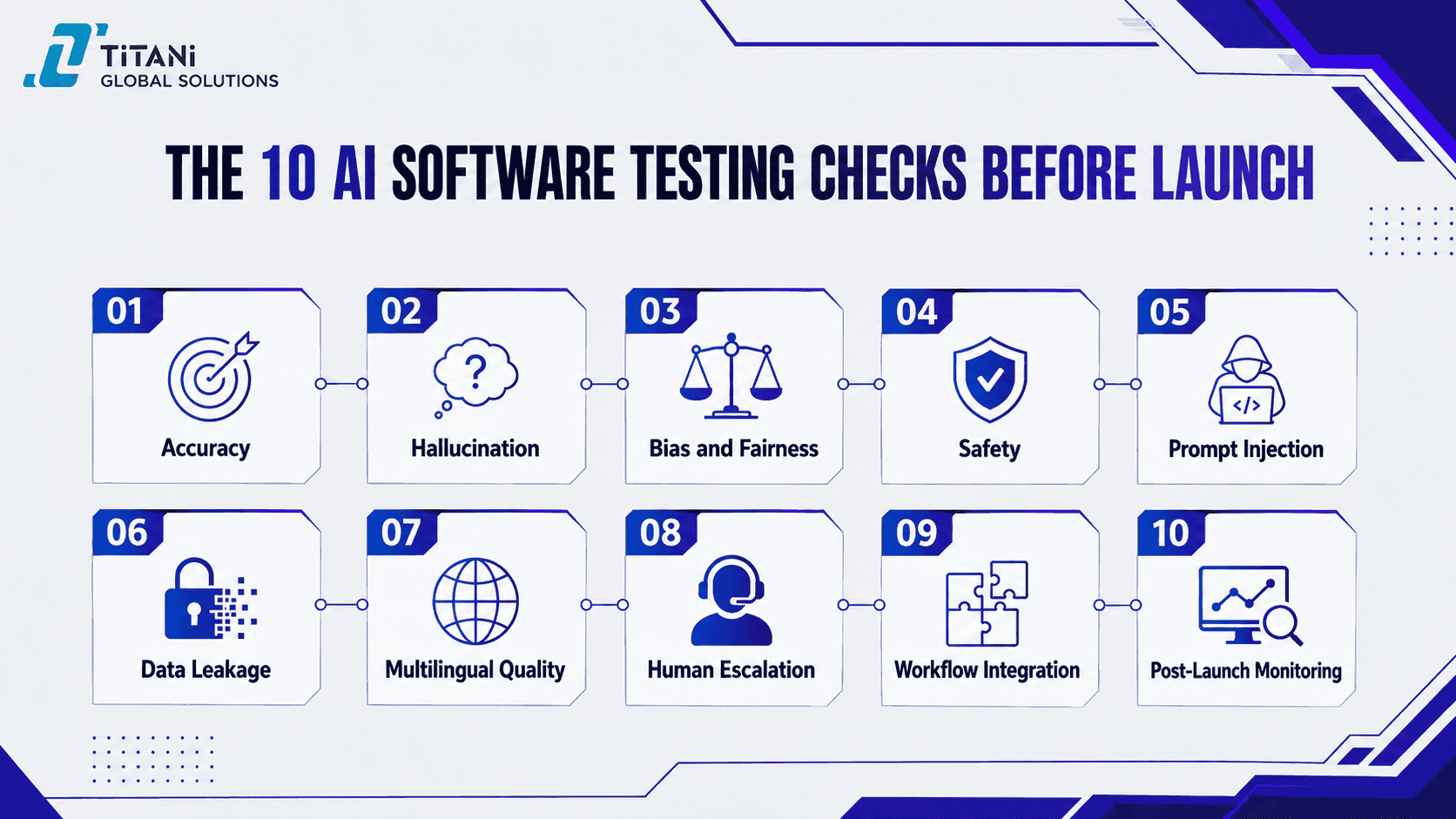
6. Data Leakage
Data Leakage occurs when the AI exposes sensitive information that should remain private. This may include customer data, employee data, financial details, contracts, internal documents, system instructions, or operational records. The risk increases when AI connects to CRM, ERP, ticketing, or document systems.
Ask: Does the system respect user permissions? Can one user access another user’s data through AI responses?
7. Multilingual Quality
Many UAE enterprises serve users in English, Arabic, and mixed-language conversations. An AI system may perform well in English but fail when users switch languages, use local phrasing, or provide informal input. Multilingual testing should validate intent, tone, context, and business meaning across languages.
Ask: Does the AI understand English, Arabic, and mixed-language prompts? Are Arabic responses accurate, natural, and appropriate?
8. Human Escalation
AI should not handle every situation alone. Some cases are too sensitive, complex, unclear, or high-risk and should be passed to a human. Human Escalation is critical for customer complaints, compliance-related questions, financial issues, healthcare workflows, and cases involving personal data.
Ask: Does the AI escalate high-risk or unclear cases? Does the human agent receive enough context to continue the interaction?
9. Workflow Integration
AI-powered software often works inside a larger business workflow. It may connect with CRM, ERP, payment systems, ticketing tools, document systems, analytics platforms, or internal approval processes. Testing the AI in isolation is not enough if the next workflow step still fails.
Ask: Does the AI trigger the right next step? Does it avoid unauthorized or incorrect actions?
10. Post-Launch Monitoring
AI software testing does not end at launch. AI-powered systems can change in performance over time due to model updates, data changes, user behavior, new prompts, or workflow changes. Post-Launch Monitoring helps teams detect issues early and improve the system continuously.
Ask: What errors should trigger review? Who owns ongoing monitoring and improvement after launch?
How to Apply the 10 Checks by AI System Type
The 10 checks above should be applied across all AI-powered systems. However, each system type has different risk priorities. Use the same check names below to trace each priority back to the main checklist.
AI System Type | Priority Checks |
AI chatbots and virtual assistants | Accuracy, Hallucination, Multilingual Quality, Human Escalation |
AI agents | Safety, Prompt Injection, Data Leakage, Workflow Integration |
LLM-based applications | Hallucination, Prompt Injection, Data Leakage, Post-Launch Monitoring |
Intelligent document processing systems | Accuracy, Workflow Integration, Human Escalation, Post-Launch Monitoring |
Recommendation engines | Bias and Fairness, Accuracy, Safety, Post-Launch Monitoring |
Voice agents | Accuracy, Multilingual Quality, Safety, Human Escalation |
Computer vision systems | Accuracy, Bias and Fairness, Safety, Post-Launch Monitoring |
AI automation workflows | Safety, Data Leakage, Workflow Integration, Human Escalation |
These priority checks help teams decide where to start. For example, an AI chatbot should be tested heavily for wrong answers, hallucinated policies, Arabic handling, and escalation failures. An AI agent requires deeper testing around unsafe actions, Prompt Injection, Data Leakage, and workflow boundaries. An intelligent document processing system should prioritize extraction accuracy, exception handling, and downstream workflow impact.
The table does not replace the full 10-check validation process. For enterprise AI systems, especially in customer-facing or regulated environments, every check should still be reviewed before launch.
Human Review Still Matters in AI Software Testing
AI-powered systems can produce answers that look correct, sound natural, and follow a logical structure. But that does not always mean the output is accurate, safe, or appropriate for the business context. This is why human review remains a critical part of AI software testing.
Automated checks can help identify repeated failures, inconsistent outputs, risky prompts, and technical issues. However, human reviewers are still needed to evaluate meaning, tone, business logic, ethical risk, customer impact, and compliance sensitivity. A response may be technically fluent but still wrong for the user, the brand, or the situation.
Human review should involve more than QA engineers. Depending on the use case, product owners, business analysts, domain experts, compliance stakeholders, and customer support teams may need to review high-risk outputs. Their role is to judge whether the AI behaves appropriately in real business conditions, not only whether the software passes a technical test.
For UAE enterprises, this is particularly important when AI systems handle multilingual conversations, regulated workflows, customer data, financial processes, or government-related services. These environments require more than automation. They require judgment, accountability, and clear escalation paths.
How to Measure ROI from AI Software Testing
ROI from AI software testing should not be measured only by how many test cases were completed. For AI-powered systems, the real value comes from preventing costly failures before they reach customers, employees, partners, or regulated workflows.
A useful way to measure ROI is to connect testing outcomes with business impact. If an AI chatbot gives fewer incorrect answers after testing, the business may reduce support escalations and customer complaints. If an AI document processing system catches extraction errors before launch, the team may avoid manual rework, billing issues, or operational delays. If an AI agent is tested against Prompt Injection, Data Leakage, and Workflow Integration risks, the enterprise may reduce the chance of unsafe actions or unauthorized access.
Useful ROI indicators include:
ROI Area | What to Measure |
Incorrect AI responses reduced | Fewer wrong, unsupported, or misleading answers reaching users |
Manual correction reduced | Less time spent fixing AI mistakes after deployment |
Support escalation reduced | Fewer tickets caused by poor AI responses or failed handoffs |
Production incidents reduced | Fewer failures linked to AI behavior in real workflows |
Compliance and audit risk reduced | Better documentation, review, and traceability before release |
Customer experience improved | More stable, accurate, and helpful AI-assisted journeys |
Time-to-market improved | Fewer approval delays because risks, safeguards, and launch conditions are clearly documented |
The key is to define the baseline before testing begins. Teams should know how many incorrect answers, manual corrections, support tickets, escalation failures, workflow errors, or approval delays occur before improvements are made. After AI software testing, they can compare the results and show whether the system has become safer, more reliable, and more business-ready.
For enterprise leaders, this matters because AI ROI is not only about automation savings. It is also about trust, governance, and speed. A system that is tested properly gives decision-makers more confidence to scale AI responsibly and can accelerate time-to-market by reducing internal bottlenecks, unclear risk ownership, and approval delays.
How to Start an AI Software Testing Pilot
For many enterprises, the best way to begin AI software testing is not to test every AI use case at once. A focused pilot is usually more practical. It helps the team validate one high-risk AI-powered system, measure the results, and build a repeatable testing model before scaling.
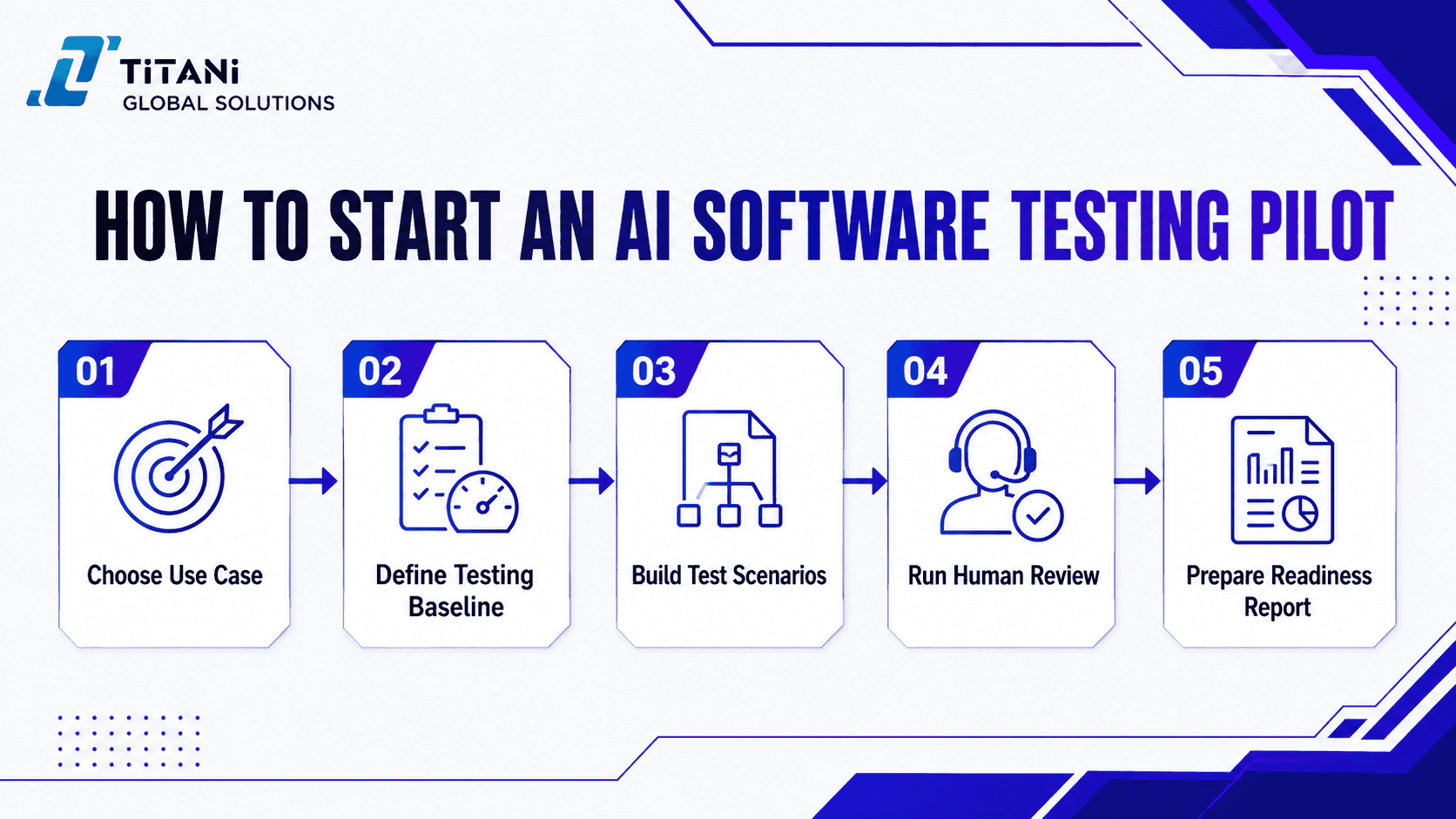
Step 1: Choose one AI-powered use case
Start with a use case that has clear business impact. This could be an AI chatbot for customer service, an AI agent for workflow automation, an intelligent document processing system, a recommendation engine, or an LLM-based internal assistant.
A good pilot use case is usually customer-facing, connected to sensitive data, linked to revenue or service quality, integrated with internal systems, or under approval pressure from business stakeholders.
Step 2: Use the 10 checks as baseline criteria
The 10 checks above should become the baseline for defining what “safe enough to launch” means. The team should clarify which risks block launch, which risks can be accepted with safeguards, which issues require Human Escalation, and which outputs require human review.
This turns AI testing from a vague quality activity into a clear release-readiness process.
Step 3: Build a test scenario library
Create a test scenario library based on real user behavior and business workflows. This should include normal cases, edge cases, unclear prompts, adversarial prompts, multilingual inputs, sensitive data scenarios, and end-to-end workflow actions.
For UAE enterprises, the scenario library should also include English, Arabic, and mixed-language conversations where relevant.
Step 4: Run validation with human review
Once the scenarios are ready, run the AI software testing pilot and review the outputs with the right stakeholders. QA engineers can validate technical behavior, while product owners, domain experts, business users, compliance teams, and customer support teams review high-risk outputs.
This step is especially important when AI responses sound fluent but may still be wrong, incomplete, unsafe, or inappropriate for the business context.
Step 5: Prepare a release-readiness report
After testing, summarize the findings in a release-readiness report. This report should not be a long technical document for QA teams only. It should help business and technical stakeholders understand what was tested, what risks remain, and what decision can be made before launch.
A practical release-readiness report should include:
Report Area | What It Should Explain |
AI use case tested | What AI-powered system was tested and which workflows were covered |
Results across the 10 checks | How the system performed across Accuracy, Hallucination, Bias and Fairness, Safety, Prompt Injection, Data Leakage, Multilingual Quality, Human Escalation, Workflow Integration, and Post-Launch Monitoring |
High-risk findings | Which issues could affect customers, operations, compliance readiness, or business continuity |
Unresolved risks and safeguards | Which risks remain open, what must be fixed, and what can be managed with restrictions |
Launch decision | Whether the system is ready to launch, needs limited rollout, requires more testing, or should be paused |
The report should give leaders enough evidence to answer one practical question: is this AI-powered system safe enough to launch in real business conditions?
Quick Self-Audit: Are You Ready to Launch?
Before launching an AI-powered system, enterprise teams should take one final step back and ask whether the system is truly ready for real users. This self-audit is not a replacement for the 10 checks above. It is a quick way to confirm whether the most important risks, responsibilities, and launch conditions have been reviewed.
Ask these questions before release:
- Have we completed the 10 AI software testing checks above?
- Have we identified the top priority checks for this specific AI system type?
- Have we tested English and Arabic user scenarios where relevant?
- Have we tested vague, incomplete, adversarial, and high-risk user inputs?
- Have we reviewed high-risk AI outputs with human reviewers?
- Have we tested the AI inside the real business workflow, not only in isolation?
- Have we documented unresolved risks before launch?
- Have we defined who owns Post-Launch Monitoring?
- Have business stakeholders approved the final launch decision?
If several answers are still unclear, the system may not be ready for full deployment. In that case, a limited rollout, additional validation, or stronger monitoring plan may be safer than launching to all users at once.
Need help validating your AI-powered system before launch? Contact Titani’s QA and AI experts to assess accuracy, safety, security, compliance, and reliability risks before deployment.
Why UAE Enterprises Choose Titani for AI Software Testing
AI-powered systems need more than a standard QA checklist before launch. They need a testing partner that understands software quality, AI behavior, enterprise security, workflow integration, and business risk. For UAE enterprises, this becomes even more important when AI systems support customer-facing services, internal automation, sensitive data, or multilingual user journeys.
Titani Global Solutions represents Titan Technology’s regional focus for businesses across the UAE and GCC, combining Middle East market orientation with Titan’s engineering foundation in Vietnam. Titan Technology was founded in 2013 and has grown with 300+ resources across its development centers. Its core capabilities include full-cycle software development, maintenance and support, monitoring and support, and testing and automation.
This foundation matters for AI software testing because AI-powered systems rarely operate alone. They often sit inside larger platforms, connect with business systems, and depend on secure workflows, reliable integrations, and strong QA practices.
For AI-powered software, Titani can support testing across use cases such as AI chatbots, AI agents, LLM-based applications, intelligent document processing, voice agents, and AI workflow automation. Our approach focuses on practical enterprise risks, including Accuracy, Hallucination, Bias and Fairness, Safety, Prompt Injection, Data Leakage, Multilingual Quality, Human Escalation, Workflow Integration, and Post-Launch Monitoring.
Security and trust are also central to this process. Titan applies CMMI Level 3 best practices and follows ISO 27001:2022 standards for information security management. For UAE enterprises working with customer data, internal documents, financial workflows, or regulated processes, this security-first foundation helps reduce risk during testing, validation, and long-term support.
Titani is also well positioned for Middle East requirements. UAE and GCC businesses often need English and Arabic-ready solutions, flexible collaboration, compliance-aware delivery, and support for business-critical systems. AI software testing should reflect that reality. It should validate not only technical performance, but also user experience, data boundaries, escalation rules, and business readiness.
The goal is simple: help your enterprise launch AI-powered systems with greater confidence, stronger safeguards, and clearer evidence that the system is ready for real users.
Talk to Titani’s QA and AI experts to assess whether your AI-powered system is accurate, safe, secure, and ready for deployment.
Conclusion
AI-powered software can create real business value, but it should not be launched on trust alone. A chatbot, AI agent, LLM application, voice assistant, or intelligent automation workflow may perform well in a demo, yet still fail when it meets real users, unclear prompts, sensitive data, multilingual conversations, and complex business workflows.
For UAE enterprises, AI software testing should be understood as a readiness process. It helps teams validate whether an AI-powered system is accurate, safe, secure, reliable, compliant, and ready to support real business operations.
The strongest approach is to start with one high-risk AI use case, test it deeply, involve human review, document unresolved risks, and scale only when the system is proven ready.
Ready to validate your AI-powered system before deployment? Contact Titani to discuss the right AI software testing approach for your use case.

